はじめに
保険業界は現在、大変革の時期を迎えています。COVID-19の余波、急激な金利上昇とインフレ圧力、人工知能(AI)、大量データの活用など、その全てが通常業務に明らかな影響を与えています。
これらの課題に直面するエンドユーザーおよび利害関係者に対して、タイムリーに正確で有益な情報を作成することは、アクチュアリーとって今まで以上に重要になっています。一件別数理モデルは正確ですが、急速に変化する世界で効果的かつ迅速に対応するには、費用も時間もかかります。そのため、アクチュアリーは通常、複雑な保険商品への対応、急速に変化する監督規制への対応、あるいは経営幹部からの「what if」分析のリクエストの増加などに対して、モデルの実行時間を短縮するため、何らかのプロキシ(近似)モデリングを採用しています。
このような技術の活用が進んでいる背景として、固定費が発生するオンプレミスのソリューションから、分散処理によりオンデマンドで拡張可能なクラウドソリューションへの移行が業界全体で徐々に進んでいることがあげられます。クラウドへの移行により、オンプレミスのソリューションに比べて固定費が減少し、変動費が増加します。変動費の増加の要因は様々ですが、特にジョブをクラウドに送信するタイミングや方法がモデルガバナンス規定に沿って行われているかに大きく左右されます。各社のユーザーの行動によっては、こうしたジョブの計算コストが劇的に膨らむ可能性があり、ユーザーがランを実行する内容に注意を払わなければ、予期せぬ多大な支出を招くことがあります。
このような計算コストの削減に役立つプロキシモデリング手法の一つが、クラスターモデリングです。これによりユーザーは、「重い」業務用モデルの「軽量」版をクラウドに効率的にサブミットすることで、重いモデルよりも高速に実行することができます。軽量モデルは重いモデルを何らかの形で縮小したものですが、それでも重要な特徴やその基礎にある経済的実態を実質的に捉えています。なお、クラスタリングを含めた何らかのプロキシモデリング手法を検討する以前の問題として、まずはモデルコード自体についてレビューを行い最適化・効率化を行うことが望まれます。本稿は、こうした作業は完了している前提で、クラウド上で実行することに伴う計算コストに課題を抱えている会社を想定しています1。
クラスターモデリングは、その名が示すように、統計的な意味で確立されたクラスタリング理論を利用したものです。この手法は、特性が類似した複数の「ポイント」(負債のモデルポイント、経済シナリオ、資産のCUSIP2番号など)をひとつのポイントにまとめて自動的にマッピングすることで、ユーザーが指定した圧縮率を確保しつつ、重いモデルとの乖離率を一定の合理的許容範囲内に保持するようにするものです。主要な財務指標に関する特性が類似していると考えられる複数のポイントをまとめたクラスターにマッピングすることで、相対的に堅牢ではない方法(例えば、性別や契約年齢などによる負債モデルポイントの圧縮)でグループ化する従来のモデル圧縮技術よりも、結果の精度を高め、より高いレベルの圧縮が可能です。本稿では取り扱わない事項もカバーした数理モデリングに関するクラスタリング手法の入門書として、 Avi Freedman と Craig Reynolds による本トピックに関するレポート3もご覧ください。また、Michail Athanasiadis、Peter Boekel、Karol Maciejewski、Dominik Sznajderによるクラスタリング手法のバリエーションに関する最新のテクニカルレポート4も、クラスタリング・プロセスの基本を理解している読者には興味深いと考えられます。
クラスタリングと米国財務報告基準における主な業績指標
公正価値ベースの責任準備金は通常、一連の(リスクニュートラルな)確率論的経済シナリオに対する結果の算術平均として計算され、各シナリオには実質的に均等なウエイトが配分されます5。当該結果にゼロフロアを適用するような監督規制はないため、理論上ゼロまたは負値となることもあります。クラスタリングの観点から見ると、公正価値として使用される平均値に対して下限(または上限)がないことは、ある種の対称性を意味し、他の全てが同じであれば、クラスターキャリブレーションプロセスには「人工的な制約」が相対的に少ないことを意味します。また、一連の確率論的リアルワールドシナリオに対して平均の結果を求める場合も同じことが言えます。つまり、この文脈でリスクニュートラルシナリオを使用することに、特別な意味はありません。むしろ、財務報告の測定基準や主要業績評価指標(KPI)こそが重要であり、その測定基準を規定する大元のフレームワークがカギとなります。KPIが算術平均である場合、例えば、経済シナリオを負債モデルポイントごとに変化させるなど、他のプロキシモデリング手法も有効です。モデルポイントの数が多い場合、この手法では、平均値への収束に必要となる経済シナリオの数を、従来的手法よりも通常少なくすることができます。
これに対し、米国のプリンシプルベースの法定責任準備金および資本のフレームワークでは、(リアルワールドの)確率論的経済シナリオの一部のシナリオに対する算術平均として定義される条件付きテール期待値(CTE)の結果を使用します。変額年金の場合、VM-21におけるプリンシプルベースの責任準備金(PBR)には CTE706 、C-3 Phase II の総資産要件には CTE98 を計算します7。経済シナリオは、アメリカン・アカデミー・オブ・アクチュアリーズの金利ジェネレーター(AIRG)を用いて、四半期ごとに作成するよう規定されています。変額年金の法定報告フレームワークでは、重いモデルを用いた場合、AIRGによって生成された10,000本の経済シナリオ8のすべてに対して一件別保有契約ファイルを用いたランが必要となることとなります。少なくとも理論的には、様々な業務目的でこの重いモデルを何回か実行する必要がありそうです。例えば、ダイナミックヘッジの有無9や異なる再投資戦略(会社の実際の戦略と規定された代替投資戦略(Alternative Investment Strategy))、あるいは異なる前提条件(各社の保守的前提(プルーデント・エスティメイト)に加え、標準プロジェクション(Standard Projection)に対して規定された前提条件)でも、モデルを実行しなければならないかもしれません。これには明らかに膨大なランタイムが必要であり、それに伴うクラウド計算処理費用も高額となります。
シナリオおよび負債のクラスタリング
変額年金を販売する会社の多くは、シナリオ、負債、資産を圧縮した軽量モデルを作成し、前述の各種バリエーションを実行しています。シナリオについては、一般的にAIRGを用いて生成される10,000本の経済シナリオの中から、一部のシナリオを抽出します。AIRGはこの目的のためのシナリオ・ピッキング・ツールを提供していますが、シナリオの抽出指標(ロケーション変数10)として金利のみを採用しており、株式と金利の両方を考慮することはできません。一方クラスタリング手法では、シナリオの選択に任意の数のロケーションパラメータを利用できるため、株式および金利の両者の動きを捉えることができます。(このアプローチを、「Type I Scenario Clustering」と呼びます。)株価指数連動型商品や変額商品など、この両者の資本市場における変動が重要な商品を取り扱う会社にとっては、大きなメリットとなります。しかし、最低保証死亡給付金(GMDB)特約、変額年金の最低保証生存給付金(VAGLBs)、またバッファや下限がある場合などの複雑な仕組みを持つ商品を取り扱う会社や、ヘッジを導入している会社では、さらに軽量なモデルを構築すべく、まず負債のクラスタリングを行い、次に軽量モデルのアウトプットをシナリオ・クラスタリングのキャリブレーションに使用することで、より堅牢なシナリオ・クラスタリングを行っています。
法定監督規制目的のために変額年金の負債クラスタリングを行う場合、計算結果の特性を代表する3から5本の経済シナリオに対して重いモデルを実行します。インプットたるシナリオの特性に焦点を当てるのではなく、このキャリブレーションに用いたシナリオに対する重いモデルのアウトプットを用いて、負債のクラスタリングを実行します。重要なのは、このプロセスにより、重いモデルに実装された動的保険契約者行動の影響が、軽量モデルにおいても自動的に捉えられていることが保証されることです。
次のステップとして、さらに圧縮率を高め、例えば0.1%や 0.01%にクラスタリングした高圧縮の負債保有ファイルを作成することで、より堅牢なシナリオ・クラスタリングを行います。高圧縮負債保有ファイルを用いた軽量モデルと重いモデルとのモデルフィットは、一般的にあまり好ましくないレベルになると思われます。しかし、高圧縮保有ファイルを使用する目的は、エンドユーザーがその後のプロセスで使用するための結果を算出することではなく、シナリオ・クラスタリングをより効果的に行うことです。(このアプローチを、「Type II Scenario Clustering」と呼びます。)高圧縮負債ファイルを用いれば10,000シナリオ全てに対してモデルを実行することが可能になり、そのアウトプット自体を財務報告目的に用いるにはやや精度に欠けるものの、各シナリオが計算結果に与える影響(特性)を捉えたものであるため、単にインプットたるシナリオのみに焦点を当てたアプローチよりもシナリオ抽出にあたってはるかに有益な情報を得ることができます。この高圧縮モデルによるラン結果を利用することで、10,000シナリオの中から使用すべきシナリオを自動的かつより適切に選択することが可能となります11。
(訳注:抽出されたCTE計算用のシナリオに対し一件別モデル、あるいは低圧縮モデルで計算を実行し、その平均値を財務報告数値として用いるものです。(内部モデルによる)金利リスク計算にあたって99.5パーセンタイル相当を求める場合、10,000本から当該手法により99.5パーセンタイル付近のシナリオを5-10程度抽出するといった活用方法(当該少数のシナリオについて重いモデルを実行し、例えばその中央値、あるいは中央付近の数本のシナリオの平均値を用いる)も考えられます。本邦経済価値ソルベンシーにおけるリスクシナリオ下のTVOGやMOCEの計算や、事業計画策定時の保険負債の経済価値およびリスク量の将来プロジェクションにも有効活用が可能と考えられます。)
実務への応用と課題
このようにクラスタリングを用いることで、軽量モデルを活用して導出した CTE値が、(10,000シナリオ全てに対して)重いモデルをランして得られたであろう数値からの乖離を妥当な許容範囲内に収める可能性を高めることができます12。とはいえ、あらゆるプロキシモデリング手法と同様に、クラスタリングではしばしばアクチュアリー(さらには会社)にとって最も重要であるものとそれほど重要ではないと考えられるもののバランスを取ることが求められます。例えば、CTE98 の法定資本の保全が会社にとって本当に重要である場合、そこに焦点を絞ることに よって、(例えば)CTE70 の準備金には若干多めのノイズが生じる可能性があると認識して受け入れた上で、軽量モデ ルがその KPI に緊密にフィットするようクラスタリングを較正することが可能です。一般に、同時に異なるKPIに対してフィットさせるには、計算結果の変動特性を捉える複数のシナリオと適切なロケーションパラメータを選択することによりキャリブレーションを行います。KPIの数を増やし、全てのKPIに緊密なフィットを維持することは、困難です。多くの異なる KPI に対して緊密にフィットするよう較正すると、全体的にフィットが悪くなる可能性が高まります。
実際には、CTE値に非対称性や非線形性がある場合もあります。例えば、アウト・オブ・ザ・マネーの変額年金のようにテールシナリオにおいてキャッシュバリューを下限とする規制が影響力を持つ場合や13、追加標準プロジェクション値(Additional Standard Projection Amount)(計算されたPBRリザーブへの加算額)がゼロでない場合などがあります。こうした非対称性は、クラスタリングを含め、使用するプロキシモデリング手法の有効性を低減させる可能性があります。このような場合でも、妥当な水準のフィットを達成できないわけではありませんが、実際のクラスタリング実務はサイエンスというよりアートに近く、徹底した分析が必要となるため、経験豊富な実務担当者の関与が必要となります。ただし、これは概ね実務導入時にのみ必要と考えられ、一度キャリブレーション実務が確立されれば、対象とする実務が本質的に変わらない限り、年に一度レビューを行う程度で問題ないと考えられます。
負債のクラスタリングが認められない場合もある点には留意が必要です。例えばU.S.GAAPが定めたLong Duration Targeted Improvementsでは、Market Risk Benefitの計算対象となる契約は、一件別にモデル化する必要があります。こうした点でシナリオ削減技術(シナリオ・クラスタリングなど)の使用は、クラウド上で必要となるランタイムを短縮するための有効な代替策となります。クラスタリングのセグメントを定義することも、実務における重要課題です。セグメントという概念は、負債の観点から見るとおそらく最も容易に理解できると考えられます。セグメントとは、クラスタリング・アルゴリズムがモデルポイントをあるセグメントから別のセグメントにマッピングしないような仕切り(あるいは区分)を意図的に作成することです。多くの実務でセグメントは当然ながらに行うことが必要です。例えばU.S. GAAPにおけるコホート設定にあたっては、ニューヨーク州内発行の契約とそれ以外の州発行の契約(前者はニューヨーク州金融サービス局による規制の対象)、帰属する法人の異なる契約や、商品種類(例えば、変額年金と登録指数連動型年金は、いずれもVM-21とC-3 Phase II両方の対象であり、まとめてモデル化する場合があります)による区分を検討します。しかし一般論として、セグメントが増えるほど、クラスタリング・アルゴリズムに制約が生じ、良好なフィットで高い圧縮率を達成する軽量モデルの構築が難しくなることに注意が必要です。報告や分析のための粒度の要件がない場合、セグメントの追加は通常、フィットを悪化させることとなります。
また一般的に、クラスタリングで達成できる圧縮率は、一件別(または非圧縮)保有ファイルに含まれる契約件数または負債のモデルポイント数に正比例します。特定のモデルフィットを達成できる圧縮率は、保険契約数が少ないほど、低くなるのが一般的です。
クラスタリングはもちろん、どのプロキシモデリング手法でも実務上決定しておくことが必要な事項があります。例えば、エンドユーザーが求める KPI を用いて較正を行うことが重要です。KPIとしては、公正価値ベースの責任準備金(算術平均)、VM-21責任準備金(CTE70)、C-3 Phase II資本(CTE98)等が考えられます。負債のクラスタリングを行う場合、個別の測定基準に対してそれぞれクラスタリングした負債保有ファイルを作成する必要はなく、むしろ、そうしたKPI全てに十分に堅牢であるように、クラスターを較正することができるという点は重要です。これを達成するには、多くの場合、専門家の判断を必要とし、その際にはサイエンスだけでなくアートが求められます。また、モデルのフィットと一件別の結果のバランスも考慮すべき点です。「類似」契約をマッピングする基本的手法であっても、純粋な一件別アプローチと比較すると、何らかのノイズが生じます。保有レコード件数を大きく減らす際は、許容できるノイズの限界を経営陣が設定する必要があります。最適な負債クラスターの結果を得るためには、従来の圧縮モデルではなく、一件別モデルに対して較正することがベストです。そうでなければ、間違った結果を再現するために多大な労力をかけることになってしまう場合があります14。
最後に、クラスタリング自体が様々な手法を包含する場合があることを挙げておきます。手法の選択は必ずしも自明ではありません。この考察についての議論は本稿の対象ではありませんが、読者の皆様には、先に参照したテクニカルレポートの一読をお勧めします15。
クラスタリングのケーススタディ
以下では、変額年金保険とユニバーサルライフ保険の既契約にクラスタリングを適用した場合のケーススタディを紹介します。
ケーススタディ1:変額年金への負債クラスタリングの適用
変額年金のケーススタディでは、最低保証死亡給付金(GMDB)および最低保証生存給付金である最低年金原資保証(GMAB)、最低保証年金給付金(GMIB)、最低保証生涯引出給付金(GLWB)(以下、総称してVAGLB)を提供する商品を対象としました。本ブロックについて5%の負債クラスタリング(負債保有レコード数を20分の1または95%削減)を設計・実施しました。図1は、法定フレームワークおよび公正価値フレームワークの両方について、一件別と5%クラスターの結果の比率を示したものです。法定フレームワークでは、CTE のモデルフィットを解約返戻金(CSV)超過額と解約返戻金を含んだ責任準備金総額の双方について示しています。クラウド上で全てのシナリオを実行すると、一件別のランは約半日かかるのに対し、5%クラスターのランは約1.5時間で完了し、ランタイムは90%近く短縮しました。
図1:5%クラスター÷一件別
| KPI | 5%クラスター÷一件別 (法定の結果は、CSV超過額) | 5%クラスター÷一件別 (法定の結果は、CSVを含む責任準備金総額) |
|---|---|---|
| 公正価値ベースの責任準備金 (1,000シナリオの平均) | 99.9% | |
| 法定責任準備金(VM-21): CTE 70 | 102.4% | 100.2% |
| 法定資本(C-3 Phase II): CTE 98 | 101.8% | 100.2% |
| ランタイムは約90%短縮 | ||
図2のグラフは、1,000本の経済シナリオ全てについて、一件別(横軸)とクラスター(縦軸)を用いて公正価値ベースの責任準備金を比較したものです。本データ用に計算したR2の測定値は、ほぼ100%です。平均値だけでなく、シナリオ別の公正価値ベースの責任準備金も全シナリオで非常によく合致しています(99.9%フィット)。
図2:公正価値の結果:1,000本の各シナリオについて(単位:十億)
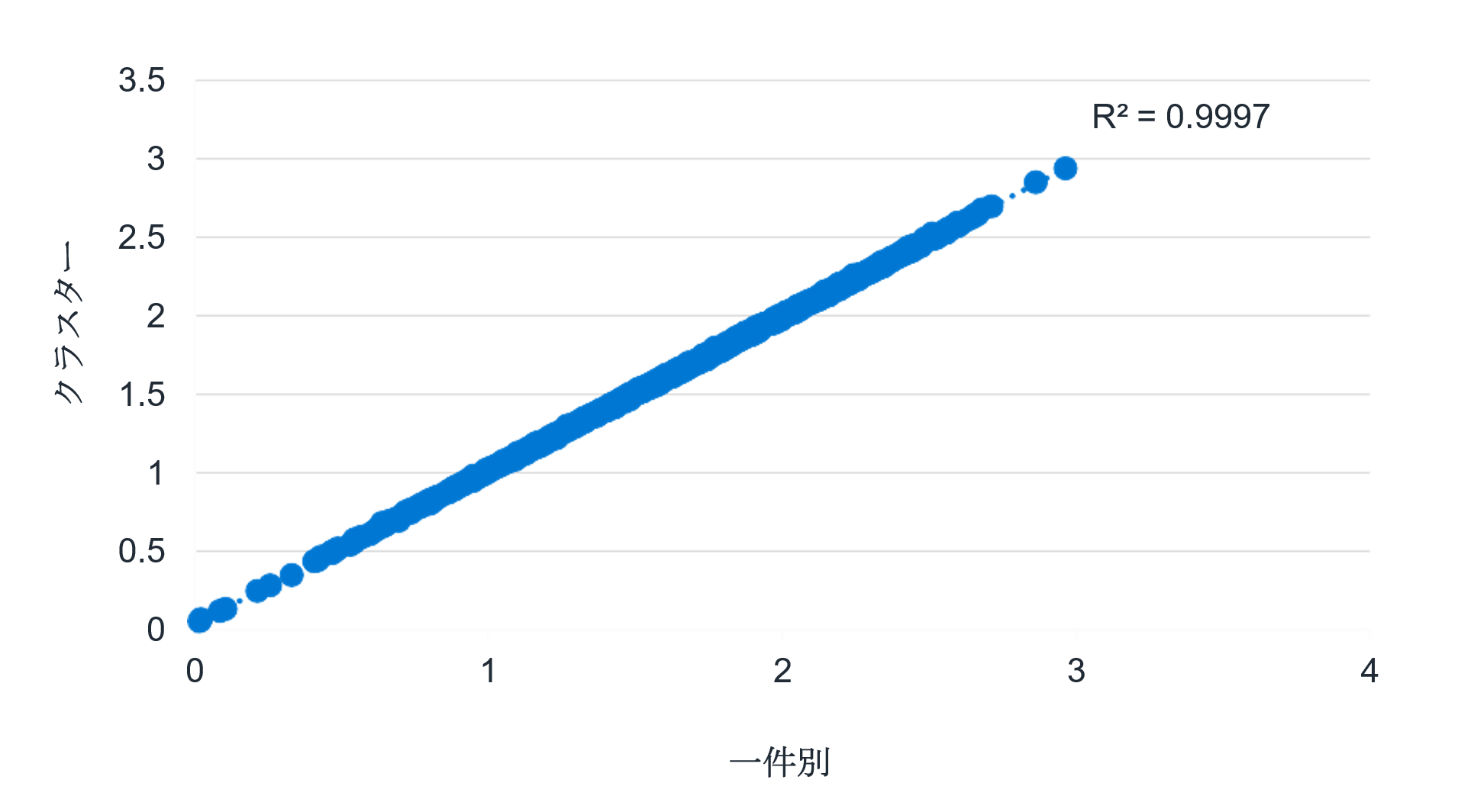
なお、負債保有ファイルを、2%(50分の1)あるいは1%(100分の1)とさらに高圧縮した場合でも、公正価値ベースの責任準備金について同程度のモデルフィットを達成できた可能性があります。本ケーススタディでは、公正価値(平均値)、VM-21責任準備金(CTE 70)、C-3 Phase II資本(CTE 98)の複数のKPIについて同時に緊密なモデルフィットを求めたため、圧縮度合を若干下げたモデルを使用することとしました。
ケーススタディ2:ユニバーサルライフへの負債クラスタリングの適用
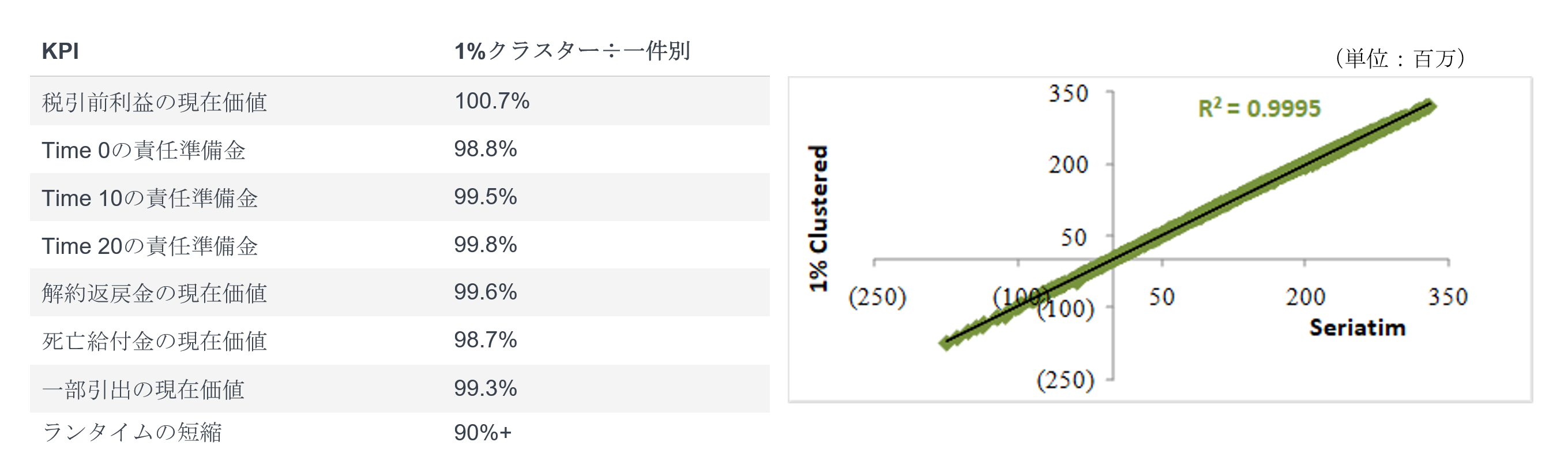
以下のケーススタディでは、ユニバーサルライフに1%(100分の1)の負債クラスタリングを適用したもので、1,000本の経済シナリオを用いた確率論的プロジェクションについてランタイムを約90%短縮しました16。これによりアクチュアリーは、経営陣のための「what-if」シナリオの分析を迅速に実行できるようになりました。図3の表は、一件別と1%負債クラスターの結果の比率を示したものです。
図3: 1000シナリオによる1%クラスター÷一件別(公正価値)
ケーススタディ3:変額年金へのシナリオ・クラスタリングの適用
ある変額年金を販売する保険会社は、シナリオ・ピッキング・ツールを用いてAIRGシナリオ10,000本から1,000シナリオのサブセットを繰り返しサンプリングしましたが、計算結果が収束しませんでした。これは、1,000シナリオのサブセットを選択する際に使用したランダムシードを変えた場合の結果が予想より大きく変動していたためです。つまり、シナリオ・ピッキング・ツールが、元になる契約の様々な指標の変動性を適切に捉えていませんでした。
10,000シナリオにType I Scenario Clusteringを用いて、モデル化されている全ての株価指数に対して較正したところ、シナリオ数を50%少なくしても結果が収束しました。検証目的で、10,000シナリオ全てとクラスタリングしたシナリオのセットで、一件別保有ファイルをランしました。その結果、法定報告に必要な CTE 70 と CTE 98 の測定基準では、それぞれ 103.0% と 98.9% のフィットとなりました。
Type II Scenario Clusteringアプローチでは、より高いモデルフィットが得られる可能性が高くなると想定されます。
その他のクラスタリング利用例
クラスタリングは、特に確率論的計算が必要となる場合、前四半期報告からの計算結果の変動要因分析を行う際に極めて有用なツールとなります。こうした変動要因には、通常、変動の影響を測定するために複数ステップのランを実行する必要があるため、ランタイムが懸念されます。
例えば、VM-21の場合、以下の変動要因分析ステップが含まれます:
- 株式市場の変動
- 金利の変動
- ボラティリティの変動
- 保有契約の変動(ファンドアロケーション、契約の脱落、一部引出などの異動)
- 前提条件の変動
- ヘッジ資産価値の変動
- 新契約
- 再保険
負債保有ファイルやシナリオをクラスタリングすることで、許容可能な精度を保ちつつこれらのステップを実行するために必要なランタイムを大幅に短縮することが可能です。別の類似利用例としては、ERM(統合型リスク管理)を目的とした感応度やストレステストを実行するケースです。この場合、アクチュアリーは、軽量モデルの重いモデルに対する全般的な近似度合いではなく、軽量モデルによる感応度(デルタ)と重いモデルによる感応度(デルタ)の近似度合いに注目することになると考えられます。
プライシングや事業計画プロジェクションなど、決定論的または確率論的プロジェクションをネストしたプロジェクションが必要な場合、高度にクラスタリングした負債保有ファイルをインナーループの責任準備金と資本の計算に使用することは、ランタイム短縮の有効な手段になります。典型的には、モデル開始日時点の一件別保有データをクラスタリングし、その結果得られたクラスタリング後の保有ファイルの時間を経過させ、将来の時点(「ノード」とも呼ばれる)のインナーループ計算にこの時間を経過させたクラスタリングした保有ファイルを使用することで、ランタイムが短縮できるでしょう。
ここに記載した利用例に関わらず、(クラスタリングにより)構築した軽量モデルが重いモデルに対して合理的にフィットすることを確認すること、できれば直近の複数の報告期間に対して、様々な感応度とストレスの下でバックテストすることが、アクチュアリーにとって重要です。このような検証は、全ての利害関係者がプロキシモデルの利用という考えに納得できるようにするため、一般的には導入当初に行われますが、こうしたテストを定期的に実行することが重要です。PBRなど特定の財務報告フレームワークでは、軽量モデルが目的に適合していることを毎年証明することを求めています。クラスタリングは堅牢なプロセスですが、特に報告期間の合間のスタッフに余力がある時期に、こうしたテストを実施することで、信頼性を高めることができます。
結論
クラスタリングは、広範な利用目的において、ランタイムを短縮し、その結果クラウド計算処理費用を削減できる可能性があります。あらゆるプロキシモデリング手法と同様に、軽量モデルの目的、ビジネス上の意味、また後続作業での用途を理解することは、プロセスを適切かつ効果的に較正する上で非常に重要です。
1 ユーザーがジョブをクラウドにどうサブミットすべきかを定めるモデルガバナンス規定自体の策定については本稿の対象外です。
2 Committee on Uniform Securities Identification Procedures、CUSIP
3 Freedman, A. & Reynolds, C. (August 2008). Cluster Analysis: A Spatial Approach to Actuarial Modeling. Milliman Research Report. Retrieved March 5, 2023, from https://www.milliman.com/en/insight/cluster-analysis-a-spatial-approach-to-actuarial-modeling.
4 Athanasiadis, M., Sznajder, D., Maciejewski, K., & Boekel, P. (January 27, 2023). Applied Unsupervised Machine Learning in Life Insurance Data. Milliman Briefing Note. Retrieved March 5, 2023, from https://www.milliman.com/en/insight/applied-unsupervised-machine-learning-in-life-insurance-data.
5 シナリオ削減手法(シナリオ・クラスタリングなど)の実装は想定しない場合。
8 AIRGが生成した10,000本の経済シナリオの大半を無視して、1,000シナリオに対して一件別保有契約を用いた重いモデルをランした結果を(おそらく盲目的に)用いる会社もあります。
9 会社が、明確に定義されたヘッジ戦略(Clearly Defined Hedging Strategy)を有する場合
10 軽量モデルで乖離率を最小限に止める対象とする項目(この事例では、20年米国国債金利)。ロケーション変数はユーザーが定義するものであるため、クラスタリング対象とする契約種類別に変えることも可能。
11 シナリオ自体に焦点をあてて10,000シナリオから抽出した場合、各シナリオに与えるべきウエイトは不均等にしなければならない可能性があります。例えば、1,000シナリオを抽出したとして、各シナリオに与えるべきウエイトが1 / 1,00ウエイトではなく、それ以上にウエイトを高くすべきものもあれば低くすべきものもあると考えられ、適宜計算結果を調整する必要が生じます。
12 他のシナリオ削減手法ももちろん有効ですが、法定監督規制目的では適用できないものもあります。例えば、(前述の通り公正価値ベースの計算に)負債モデルポイントによって適用する経済シナリオを変えることはできません。PBRでは、各シナリオの責任準備金は、定義上、当該シナリオに対する全ての契約に対する計算結果であることが必要です。契約ごとにシナリオを変えた場合、各契約ごとの計算結果を通算することができないことになってしまいます。
13 評価日時点のキャッシュバリューがPBRリザーブの下限となります。
14 一件別ファイルではなく従来の方法で圧縮した負債ファイルからクラスタリングを始めると、過去の作成プロセスで入ったかもしれないノイズがそのままクラスターに引き継がれるリスクがあります。
15 Athanasiadis, M., Sznajder, D., Maciejewski, K., & Boekel, P. (January 27, 2023), op cit.
16 クラスタリングした保有ファイルの件数が元の1%になっていると考えると、ランタイムを99%程度短縮できると期待されるかもしれませんが、モデルの初期化、資産の計算、契約単位毎には行われない計算(再投資、投資の終了、税金など)は負債クラスタリングの影響を受けないため、実際のランタイムの短縮は期待よりも若干低く90%です。